前言
GPT-4、Bloom 和 LLaMA 等大型语言模型(LLM)通过扩展至数十亿参数,实现了卓越的性能。然而,这些模型因其庞大的内存需求,在部署进行推理或微调时面临挑战。这里将探讨关于内存的优化技术,旨在估计并优化在 LLM 推理以及在多样化硬件配置上进行微调过程中的内存消耗。
首先,需要认识到大型语言模型在运行时的内存消耗主要受以下几个因素影响:
- 模型规模:模型拥有的参数数量直接决定了其对内存的需求。参数数量越多,模型文件体积越大,加载和执行模型所需的内存也就越多。
- 输入数据量:处理的输入数据量增加,也会相应增加内存的使用。例如,处理更长的文本序列或更复杂的查询任务将需要更多的内存资源。
- 并行计算:虽然并行处理可以加快模型的执行速度,但同时也可能导致内存消耗的增加,因为每个处理核心可能都需要存储模型的一部分数据。
- 优化策略:采用模型剪枝、量化或知识蒸馏等技术可以有效减少模型的大小,从而降低其内存占用。
内存计算
加载大型语言模型(LLM)所需的内存量主要受模型参数的数量和参数存储所使用的数值精度的影响。在推理过程中,内存占用主要受以下两个因素影响:
- 模型参数:加载模型本身所需的内存量。
- 激活张量:在推理过程中,模型的每层都会产生临时的激活张量,这些张量同样需要占用内存。
推理期间的峰值内存使用量可以粗略地估算为加载模型参数所需的内存与激活张量所需的内存之和。
以下估算所需内存的量示例:
- 对于以32位浮点数(即单精度浮点数)存储的模型,每十亿(Billion)参数大约需要4X GB的VRAM。
- 对于以16位浮点数(如bfloat16或float16)存储的模型,每十亿参数大约需要2X GB的VRAM。
以拥有175B(即175十亿)参数的GPT-3模型为例,若采用bfloat16精度,则加载该模型将需要大约350GB的VRAM。截至目前,市面上最大的商用GPU,如NVIDIA的A100或H100,通常仅提供最高80GB的VRAM。因此,为了有效地部署这些庞大的模型,必须采用张量并行(tensor parallelism)和模型并行(model parallelism)等技术。
量化推理内存
这里使用 OctoCode 模型来量化推理的内存需求,该模型具有大约 15 亿个 bfloat16 格式的参数(约 31GB)。将使用transformers加载模型并生成文本:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder",
torch_dtype=torch.bfloat16,
device_map="auto",
pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
prompt = "Question: Please write a Python function to convert bytes to gigabytes.nnAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
def bytes_to_gigabytes(bytes):
return bytes / 1024 / 1024 / 1024
bytes_to_gigabytes(torch.cuda.max_memory_allocated())
输出:
29.0260648727417
峰值GPU内存使用量大约为29GB,这一数值与我们估算的用于加载bfloat31格式模型参数所需的16GB内存大致相符。通过量化技术优化推理内存使用,尽管bfloat16是训练大型语言模型(LLM)时常用的数值精度,但研究人员已经发现,将模型权重量化为更低精度的数据类型,例如8位整数(int8)或4位整数,可以在最小化推理任务精度损失的同时显著减少内存使用量。这种方法特别适用于文本生成等场景,其中模型的输出主要由其生成的文本序列的质量来评估,而不是由模型的精确数值精度决定。
bfloat16、int8、int4是数据类型的缩写,它们用于在机器学习和深度学习中以不同的精度表示数值。
- bfloat16 (Brain Floating Point 16-bit):bfloat16是一种浮点数格式,提供了与32位单精度浮点数(fp32)相似的动态范围,但只使用了16位的存储空间。它在深度学习中被用于减少模型的内存占用,同时尽量保持较高的数值精度。
- int8 (8-bit Integer):int8是一种整数格式,能够表示-128到127的整数值。在深度学习模型的量化中,int8常用于减少模型大小和内存需求,加快推理速度,但相比于浮点数,它会有一定的精度损失。
- int4 (4-bit Integer):int4是一种低精度的整数格式,用于表示较小的整数值。在量化中使用int4可以进一步减少模型的内存占用,但这种精度的降低可能会导致较大的精度损失,适用于对精度要求不高的应用场景。
在深度学习中,从标准的32位单精度浮点数(fp32)到更低精度的格式(如bfloat16、int8或int4)的转换,可以在模型部署时显著减少内存占用和提高计算速度,但这种转换需要在模型精度和性能之间做出权衡。量化是实现模型优化以适应不同硬件平台的常用技术之一。
量化的优势在于它减少了模型文件的大小,从而降低了加载模型到内存中所需的空间。此外,量化还可以减少模型在推理时的计算需求,因为较低精度的运算通常比高精度的运算更快、更高效。
让我们看看 OctoCode 模型的 8 位和 4 位量化所节省的内存:
# 8-bit quantization
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True,
pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
bytes_to_gigabytes(torch.cuda.max_memory_allocated())</pre>
输出:
`15.219234466552734`
#4-bit quantization
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True,
low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
bytes_to_gigabytes(torch.cuda.max_memory_allocated())
输出:
9.543574333190918
通过采用8位量化,模型的内存需求可以从31GB降低到15GB,而进一步采用4位量化可以将内存需求减少至仅9.5GB。这样的内存优化使得在消费级GPU,如具有3090GB VRAM的RTX 15,运行拥有24B(即240亿)参数的OctoCode模型成为可能。
然而,需要注意的是,相比于4位或bfloat8(即8位浮点数)精度,更激进的量化策略(例如16位)有时可能会导致模型精度的下降。因此,用户应根据自己的应用场景仔细评估内存节省和准确性之间的权衡。
量化技术是一种强大的工具,它通过显著减少内存占用,使得大型语言模型(LLM)能够在资源受限的环境中部署,这包括云服务器实例、边缘设备,甚至是移动设备。量化不仅有助于降低模型的存储和传输需求,还可以减少模型推理时的计算负载,从而提高运行效率。
量化也会对模型的精度产生一定的影响,具体如下:
- 精度损失:量化过程中将浮点数转换为整数或更低精度的格式,这会导致数值表示的精度降低。模型权重和激活函数的量化可能会导致模型无法精确地表示其原始参数,从而影响模型的性能。
- 过拟合风险:量化可能会改变模型的学习动态,有时会导致过拟合的风险增加。这是因为量化后的模型可能更容易记住训练数据中的噪声,而不是学习泛化的模式。
- 梯度稀疏:在训练过程中使用量化可能会减少梯度的非零值数量,导致梯度稀疏。这可能会影响梯度下降算法的效率,从而影响模型的训练效果。
- 特定层的影响:量化对模型中不同层的影响可能不同。例如,深度学习网络的早期层通常对输入数据进行高度非线性变换,这些层可能对量化更敏感。
- 数据类型选择:选择不同的量化数据类型(如int8、int16、bfloat16等)对精度的影响也不同。一般来说,数据类型的位数越多,量化误差越小,但内存和计算成本也越高。
- 量化感知训练:为了减少量化对精度的负面影响,可以采用量化感知训练(Quantization Aware Training, QAT)。QAT在训练过程中模拟量化,使模型能够适应量化误差,从而在量化后保持较高的精度。
- 量化策略:不同的量化策略(如均匀量化、非均匀量化、逐层量化等)对模型精度的影响也不同。选择合适的量化策略对于在精度和效率之间取得平衡至关重要。
- 任务敏感性:不同的应用任务对模型精度的敏感度不同。例如,一些对精度要求极高的任务(如医疗图像分析)可能不适合使用量化,而其他任务(如语音识别)可能能够容忍一定程度的精度损失。
估计内存进行微调
量化确实是为了高效推理而广泛使用的技术,它通过减少模型参数的数值精度来降低模型的内存占用和加速推理过程。然而,在模型训练阶段,尤其是在微调大型语言模型(LLM)时,张量并行性和模型并行性等技术对于管理内存需求同样至关重要。
微调是指在特定任务的数据集上对预训练模型进行额外的训练,以使其更好地适应该任务。由于以下原因,微调期间的峰值内存消耗通常会比推理时高出3-4倍:
- 渐变:在训练过程中,需要存储模型参数的渐变信息,以便进行梯度下降等优化操作。
- 优化器状态:大多数现代优化器(如Adam)会存储关于模型参数的额外状态信息,如梯度的一阶和二阶矩。
- 激活存储:为了进行反向传播,需要存储前向传播过程中的中间激活值。
因此,对于具有X亿个参数的LLM,微调时的内存需求可以保守估计为大约4 * (2X) = 8X GB的VRAM,这里假设使用bfloat16精度。例如,微调一个7B(即70亿)参数的LLaMA模型,每个GPU大约需要7 * 8 = 56GB的显存以bfloat16精度进行微调。这个内存需求超出了当前大多数商用GPU的内存容量,因此需要使用分布式微调技术。
分布式微调涉及在多个GPU或机器上并行地训练模型,这样可以分散内存和计算负载,使得可以处理更大的模型或更复杂的任务。这通常需要额外的通信开销,但通过适当的优化和同步策略,可以有效地利用多个计算资源来训练或微调大型语言模型。
在微调大型模型时,除了内存需求外,还需要考虑计算资源、训练时间、模型性能和最终部署的效率之间的平衡。通过采用适当的量化、并行化技术和优化策略,可以在有限的资源下实现有效的模型微调和部署。
分布式微调技术
为了克服大型模型的 GPU 内存限制,目前有研究人员提出了以下几种分布式微调方法:
- 数据并行:经典的数据并行方法在多个 GPU 上复制整个模型,同时分割和分配训练数据批次。这会随着 GPU 数量的增加而线性减少训练时间,但不会减少每个 GPU 的峰值内存需求。
- ZeRO 第 3 阶段:一种高级形式的数据并行性,可跨 GPU 划分模型参数、梯度和优化器状态。与传统的数据并行相比,它通过在训练的不同阶段仅在每个 GPU 上保留所需的分区数据来减少内存。
- 张量并行:张量并行不是复制模型,而是将模型参数划分为行或列,并将它们分布在 GPU 上。每个 GPU 都在一组分区的参数、梯度和优化器状态上运行,从而节省大量内存。
- 流水线并行:该技术将模型层划分到不同的 GPU/worker 上,每个设备执行层的子集。激活在工作人员之间传递,减少了峰值内存,但增加了通信开销。
估计这些分布式方法的内存使用量并非易事,因为参数、梯度、激活和优化器状态的分布因技术而异。此外,不同的组件(例如变压器主体和语言建模头)可能会表现出不同的内存分配行为。
LLMem的GPU内存使用量
LLMem是一种在跨多个 GPU 对 LLM 应用分布式微调方法时准确估计 GPU 内存消耗的解决方案。
[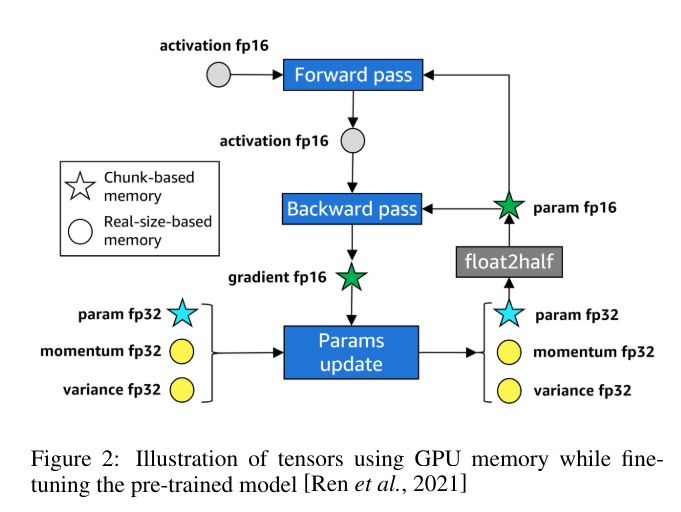
估计GPU内存使用情况以微调预训练的大型语言模型(LLM),LLMem考虑了多个因素,包括计算前重新组合参数(ZeRO的第三阶段)、反向传播中的输出收集(张量并行性),以及变换器主体和语言建模头部的不同内存分配策略。
实验结果显示,LLMem能够以高达1.6%的误差率估计在单个GPU上微调LLM时的峰值GPU内存使用量,这比最先进的DNNMem的平均误差率**42.6%要准确得多。当将分布式微调方法应用于在多个GPU上运行、参数超过10亿的LLM时,LLMem实现了平均误差率3.0%**的卓越性能。
通过提前准确估算内存需求,LLMem可以帮助用户选择最有效的分布式微调方法,避免内存不足的问题,同时尽可能减少训练时间。这种预先的估算对于确保微调过程的顺利进行和优化计算资源的使用至关重要。
当前研究现状
虽然量化、张量并行和模型并行等技术已经成熟,但研究人员仍在不断探索新方法,以进一步提高大型语言模型(LLM)训练和部署的效率。
- LoRA 和 QLoRA:这些技术涉及训练较小的残差适配器模块,用于更新预训练的LLM,使其适应新知识,而不是直接对大量参数进行微调。这种方法能够在保持模型大部分性能的同时,显著节省内存。
- FlashAttention:自注意力机制是Transformer模型中的内存和计算瓶颈。FlashAttention通过以线性复杂度逼近标准注意力机制,将输入序列长度的内存需求从二次方降低到线性,从而提高效率。
- 混合专家(Mixture of Experts):这种方法将每个输入数据样本有条件地路由到专门的专家模型,而不是让整个模型对其进行处理。这种动态稀疏性通过仅激活每个样本所需的专家子集来节省内存。
- 模型剪枝(Pruning):研究人员通过迭代删除如注意力头等相对不重要的组件,来探索模型压缩,以此在准确性和内存/速度之间做出权衡。
- 卸载(Offloading):将参数、优化器状态或激活卸载到CPU RAM或磁盘的技术,可以作为对大型模型有限GPU内存的补充,从而允许更大的模型或更长的序列处理。
这些尖端方法反映了一个活跃的研究生态系统,专注于实现在多样化硬件环境中高效训练和部署LLM的目标,推动了大型模型的民主化进程。通过这些技术,研究人员和工程师可以更灵活地在不同的应用场景中利用LLM,无论是在资源受限的个人设备上还是在大规模的云计算环境中。
结论
大型语言模型的内存要求对其在实际应用中的广泛采用提出了重大挑战。通过了解内存估计技术并利用量化、分布式训练策略和新兴创新,可以优化资源受限设备上的 LLM 部署。
LLMem 等工具为准确的内存估计铺平了道路,使用户能够选择最合适的微调配置。随着硬件的发展和研究的进步,我们可以预见更高效的训练和推理,从而推动自然语言处理和人工智能的进步。
在模型容量、准确性和资源利用率之间取得适当的平衡对于释放跨不同领域和用例的大型语言模型的全部潜力至关重要。通过采用内存优化技术,我们距离最先进的语言人工智能可访问、可扩展和可持续的未来又近了一步。